Can you spot the Error?
Peter Huber referred to “the rawness of raw data”, a kind of data we would not expect to find in a textbook. The book of Fahrmeir and Tutz on multivariate modelling refers to the visual impairment data from Liang et al., 1992 in table 3.12:

Visual Impairment Data from Liang et al. as found in Fahrmeir and Tutz
Nothing wrong here at first sight; but how would you tell? There are some people who are actually able to look at non-trivial table data and spot “the round peg in the square hole”, but that just won’t work for the rest of us.
As you might guess, I am going to make a case for graphics here.
Let’s start with what the mainstream would do: plot the data in a dotplot like thing using the trellis paradigm of conditioning. I used ggplot2 to make sure to trellis state-of-the-art. A simple
qplot(count, side, data=visual2, colour=impaired) + facet_grid(age ~ race)
gives me:
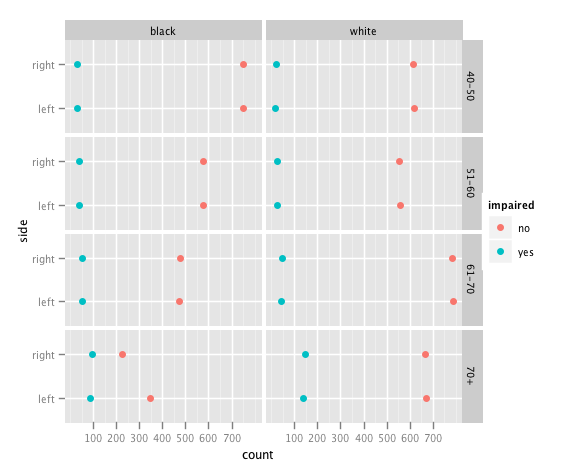 (I still have a hard time to find that syntax intuitive …) Surprisingly this plot already is sufficient to spot the “problem” in the data, although some important properties of the data can’t be seen here.
(I still have a hard time to find that syntax intuitive …) Surprisingly this plot already is sufficient to spot the “problem” in the data, although some important properties of the data can’t be seen here.
A mosaic plot makes the whole thing even easier:

(impairment cases highlighted, left and right is left and right)
The left and right cases are (what a surprise) always of the same size, except for the 70+, black – hard to believe that in this group 110 cyclops show up not having a right eye.
In the mosaic plot the higher proportion of the impaired right eyes for 70+ blacks jumps immediately to ones eyes, but what reveals the error is the missing independence between race and side for 70+. That implies that we have too few cases here, and what is ‘226’ in the table should actually be ‘336’.
Here is the (corrected) data.


Could you please provide the input R file please? I am quite new with R and haven’t the idea how to input your data into a variable yet. It will be a great help for me if you can show me how you did it. Thanks!
The link to the data file is now at the end of the post (it always meant to be, but somehow it got lost). You can load it with
visual2 <- read.table("...your path.../visual.txt")(Make sure to save the link target and not the page with the data on it, as some browsers add their own interpretation of useful white-spaces)